
Creating an optimal model that strikes a balance between underfitting and overfitting requires careful consideration. To assess how well our model performs on new, unseen data, we employ the train-test split technique and cross-validation.
Train-Test Split:
To evaluate a model’s performance, we split the dataset into a training set (approximately 70-90% of the data) and a test set (10-30%). In sklearn, the train_test_split function from sklearn.model_selection is utilized for this purpose.
Key Parameters:
The “stratify” option ensures a consistent ratio of class labels in both the training and test sets, crucial for balanced data.
The “test_size” option determines the size of the test set (e.g., 0.2 represents 20%). The “shuffle” option, set to True by default, shuffles the data before splitting.
The “test_size” option determines the size of the test set (e.g., 0.2 represents 20%). The “shuffle” option, set to True by default, shuffles the data before splitting.
Cross-Validation (CV):
When tuning hyperparameters, using the test set multiple times can lead to overfitting. To address this, we employ cross-validation. A validation set is used to fine-tune hyperparameters, and different methods like K-fold CV are employed to ensure robust evaluation.
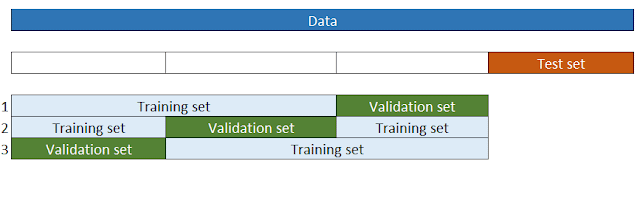
3-fold CV
CV Methods:
Leave One Out (LOO)
Leave P Out (LPO)
ShuffleSplit
KFold
StratifiedKFold (for classification tasks with class imbalance)
Stratified Shuffle Split
GroupKFold (considering groups in the data)
Leave P Out (LPO)
ShuffleSplit
KFold
StratifiedKFold (for classification tasks with class imbalance)
Stratified Shuffle Split
GroupKFold (considering groups in the data)
Cross-Validation for Time Series Data:
Time series data, characterized by patterns, requires special consideration. Randomly splitting such data is not meaningful. Scikit-learn’s TimeSeriesSplit approach and other methods like Nested CV and hv-block CV are discussed for accurate evaluation.

Cross-validation for Timeseries data
Conculsion
In this post, we have explained:
Train-test split
Cross-validation
Different approaches of CV
Cross-validation for Timeseries data
Cross-validation
Different approaches of CV
Cross-validation for Timeseries data


